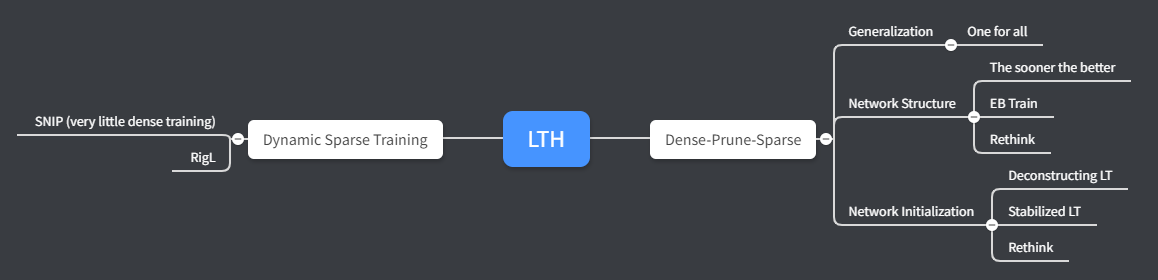
Lottery Ticket Hypothesis
Lottery Ticket Hypothesis
A randomly-initialized, dense neural network contains a subnetwork that is initialized such that—when trained in isolation—it can match the test accuracy of the original network after training for at most the same number of iterations.
Recent Surge
- Drawing Early-Bird Tickets: Towards More Efficient Training of Neural Networks:
- Discover for the first time that the winning tickets can be identified at the very early training stage, which we term as early-bird (EB) tickets, via low-cost training schemes (e.g., early stopping and low-precision training) at large learning rates.
- Futher propose a mask distance metric that can be used to identify EB tickets with low computational overhead, without needing to know the true winning tickets that emerge after the full training.
- Finally leverage the existence of EB tickets and the proposed mask distance to develop efficient training methods, which are achieved by first identifying EB tickets via low-cost schemes, and then continuing to train merely the EB tickets towards the target accuracy.
- Rigging the Lottery: Making All Tickets Winners: Propose a dynamic sparse training scheme to achieve both memory and computational efficiency and more accurate model. The proposed scheme includes four steps, initialize sparsity distribution, update schedule, drop criterion and grow criterion. During training we drops connections according to the magnitude of weight and grow new connections according to the magnitude of gradient.
- Why it is called “making all tickets winners”?
Because given any sparisity initialization, the dynamic connectivity makes sure the final performance is good. - Why it can achieve selectable FLOPs before training?
The proposed dynamic sparse training does not change required FLOPs during training, thus allow us to decide on a specific inference cost prior to training.
- Why it is called “making all tickets winners”?
- Stabilizing the Lottery Ticket Hypothesis: Revise the lottery ticket hypothesis with rewinding. Target at solving the limitation of LTH that iterative magnitude pruning (IMP) fails on deeper networks. Specifically, they modify IMP to rewind pruned subnetwork weights to their former values at iteration k rather than resetting them to iteration 0.
- Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask:
- Provide insights about why rewind to initial value is better than random re-initialization. Specifically, the only important factor is the sign of initial value, as long as you keep the sign, re-initialization is not a deal breaker;
- Provide insights about why setting pruned weights to zero is important;
- Discover the existence of supermasks that can be directly applied to an untrained, randomly initialized network to produce a model with performance better than chance.
- Rethinking the Value of Network Pruning: In large learning rate setting, initialization make no difference for the final performance while structure does. LTH experiments build on the small learning rate and shallow networks.
- SNIP: Single-shot Network Pruning based on Connection Sensitivity: Present a new approach that prunes a given network once at initialization prior to training by introducing a criterion based on connection sensitivity, the fundamental idea behind it is to identify elements (e.g. weights or neurons) that least degrade the performance when removed. This eliminates the needs of pretraining while achieves extremely sparse networks with virtually the same accuracy.
- One Ticket to Win Them All: Generalizing Lottery Ticket Initializations Across Datasets and Optimizers: Demonstrate that we can reuse the same winning tickets across a variety of datasets and optimizers.
- The State of Sparsity in Deep Neural Networks: Empirically show that training from scratch using a learned sparse architecture (LTH) is not able to match the performance of the same model trained with sparsification as part of optimization process.
- …
Theory to Support Lottery Initialization
- On the Decision Boundaries of Deep Neural Networks: A Tropical Geometry Perspective: This paper support lottery initializaiton in theory from the perspective of Tropical Geometry.
In general, this paper bridges the gap between newton polygon (a well-developed mathematical tool) and the decision boundary of neural networks, by virtue of the proposed tropical geometry theory.
In particular, we can then visulize the decision boundary through a polytope which can be generated from the neural network parameters.
This helps us to visualize the effectiveness of different initialization.

Fig.2 - Visualization of the Newton polygon of different initialization.